Extracting Text From Documents
Methods
Throughout the duration of this project, we have thoroughly examined a range of text extraction techniques. By documenting these findings, we aim to facilitate future studies, enabling them to leverage the knowledge gained from our research.
Method 1. Image Upscaling
Since the document contained an image encompassing ranks, assignments, and their types, we deemed it advantageous to extract the data from the image. However, the image itself was of notably low quality.
Our initial approach involved upscaling the image to enhance its resolution. We experimented with various combinations, including 200x and 400x upscaling. While these methods did improve the image quality to some extent, the extracted assignments remained difficult to read and comprehend. Therefore, we transitioned to employing text extraction techniques using ChatGPT to overcome this challenge.
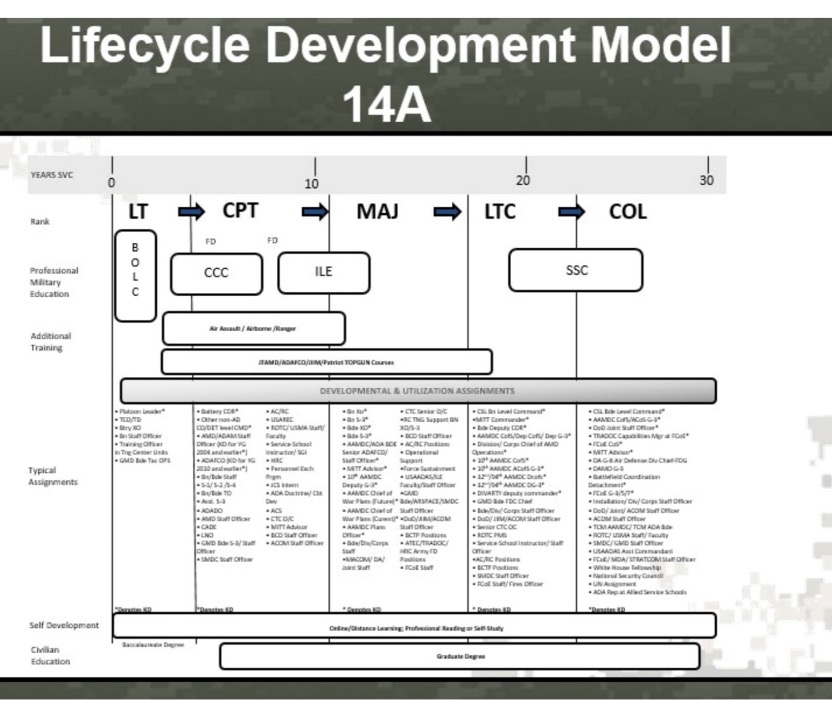
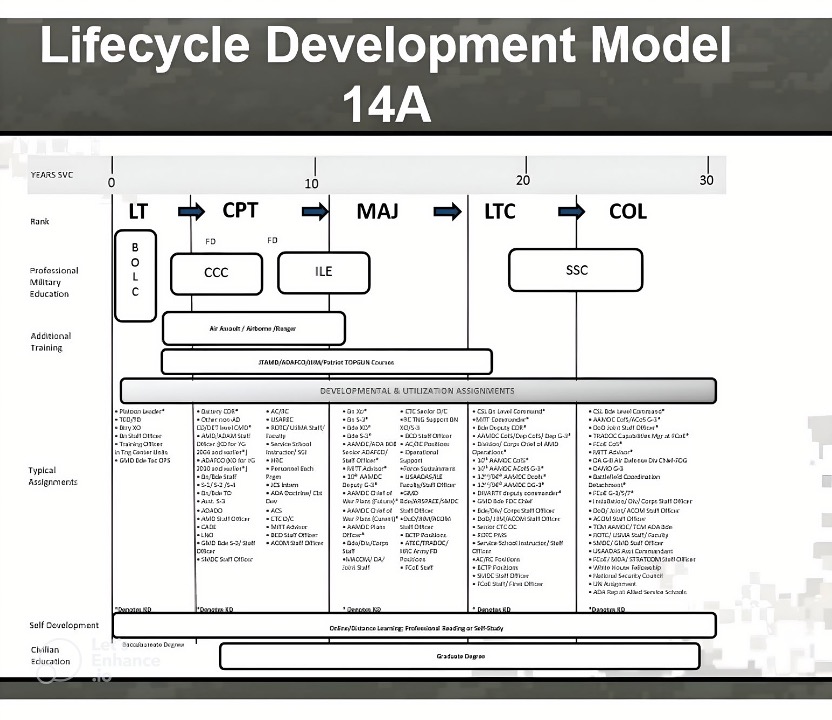
Advantages
- Improved resolution
- Reduced noise
- Time efficiency.
Disadvantages
- Distorted results
- Illegible output,
- Only partial improvement in image quality.
Method 2. Chat-GPT
The methodology employed for text extraction using ChatGPT involved providing a prompt along with the relevant section of the document containing the assignments. Multiple prompts were tested and experimented with, ultimately selecting the prompt that yielded the most accurate results.
A challenge arose as slight rearrangements of the words in the prompt led to different outputs from GPT. Another obstacle emerged when attempting to extract data for “Lieutenant Colonel” and “Colonel” assignments, as GPT failed to retrieve the desired information.

Example Chat-GPT Prompt
Advantages
- Ease of implementation
- Speed of implementation
- Ability to reuse prompts for differently formatted documents
- Effectiveness in extracting data across various test documents
Disadvantages
- Sensitive to user input
- Potentially generating varying outputs for identical prompts
- Less precision in extracting assignments
Method 3. Regular Expression (Regex)
The final method we explored to extract data from the Army documents was the use of regular expressions, which match strings of interest in the text. Unlike the ChatGPT method, writing regular expressions took more time on the part of the scientist. Since each Branch used a unique formatting style, our regular expressions had to be modified for each document. A basic function using regular expressions would iterate through each character in the document and match to the sections following bullet points.

Example Text to Use Regex to Extract Data
Example Regex Function
myfunction <- function(input){ vector <- unlist(str_split(input, pattern = "\\h\\(.\\)\\h")) return(vector) }
While this highly supervised extraction method was more time-intensive, it also allowed for the most precise extraction of assignments of the three methods explored and allowed for better control of the output format.
We chose the regular expression technique as the final method to extract data from documents. This method was the best fit for our set of data because we had a small number of documents (14), and favored reproducible results that captured the most individual assignments and their types over the more variable outputs produced by ChatGPT. We noted that if our dataset was much larger, this method would not be ideal because of how time intensive it was to make edits to the code for each document we needed to analyze. However, this method was satisfactory for completing our goals during this phase of the project.
|
|
|
Program Contacts: Joel Thurston and Cesar Montalvo |