Methods
Our Approach
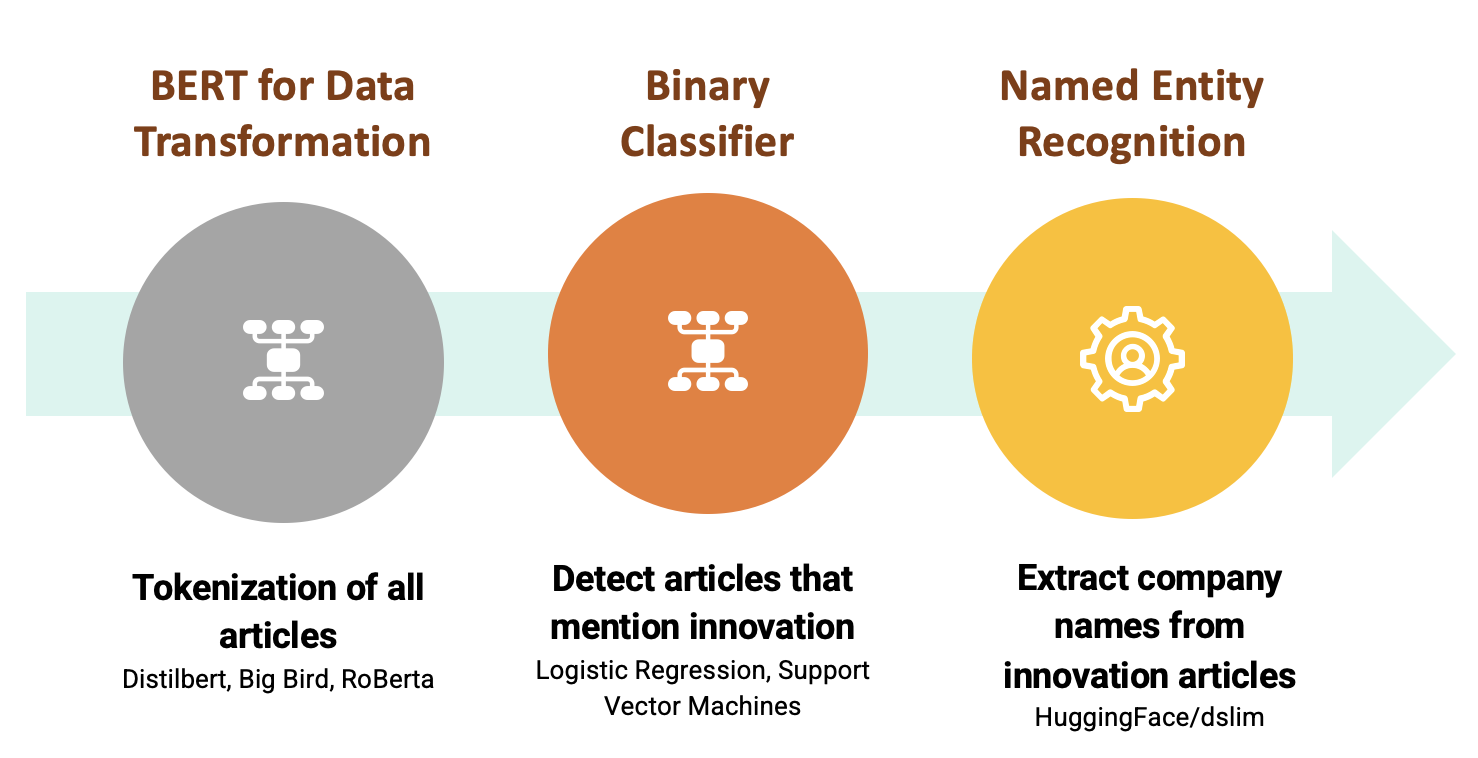
Implement various transformer based Natural Language Processing (NLP) models to tokenize and build text embeddings for the labeled data sets,
Leverage supervised Machine Learning methods to train a model using a balanced dataset to classify articles denoting innovation and not denoting innovation,
Evaluate model performance using cross-validation by using the imbalanced dataset,
Apply BERT’s Named Entity Recognition methods to extract company names from classified documents,
Run these methods to all articles for a given sector for a given year to extract the count of innovative articles per year, with their associated companies.
Transformer Based Natural Language Processing Models

What is BERT?
BERT is a pre-trained, bidirectional unsupervised Natural Language Processing model developed by Google in 2018. Trained on the Book Corpus of 2,500 million words and Wikipedia's 800 million words, BERT tokenizes and builds more complex text embeddings that take word context into account, unlike traditional "bag-of-words" approaches. Here, we use BERT in several ways: not only as a data transformation tool to convert our text data into text embeddings based on a pre-trained model for classification but also as the basis for named-entity recognition.
Try the demo here!
How do we make use of BERT for our work?
We make use of the aforementioned models and their variations provided by Huggingface for 2 processes (see Appendix for technical details).
- Data Transformation: We pre-process our documents, such that the text of our news articles are represented by new word-embeddings using these state-of-the-art NLP models. We use DistilBERT and a hybrid Big Bird-RoBERTa model for data transformation here. Once the articles are transformed, we then leverage classic supervised machine learning techniques in order to classify the articles based on likelihood of describing innovation. These include:
- Logistic Regression
- Support Vector Machines
- Named Entity Recognition: Once a set of innovation-likely articles are identified, we make use of the BERT base model for Named Entity Recogition.
BERT Models
There are several different BERT-like language representation models, usually designed to suit a specific task or optimized for a specific type of data. These include:
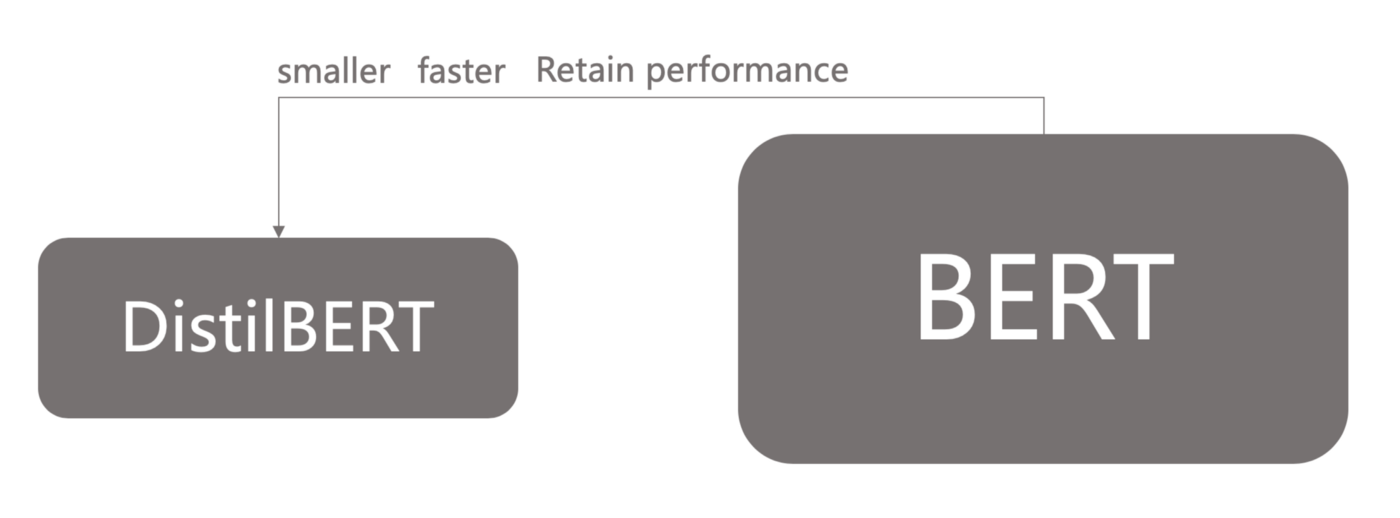
DistilBERT
Big Bird

Roberta

Cross-Validation
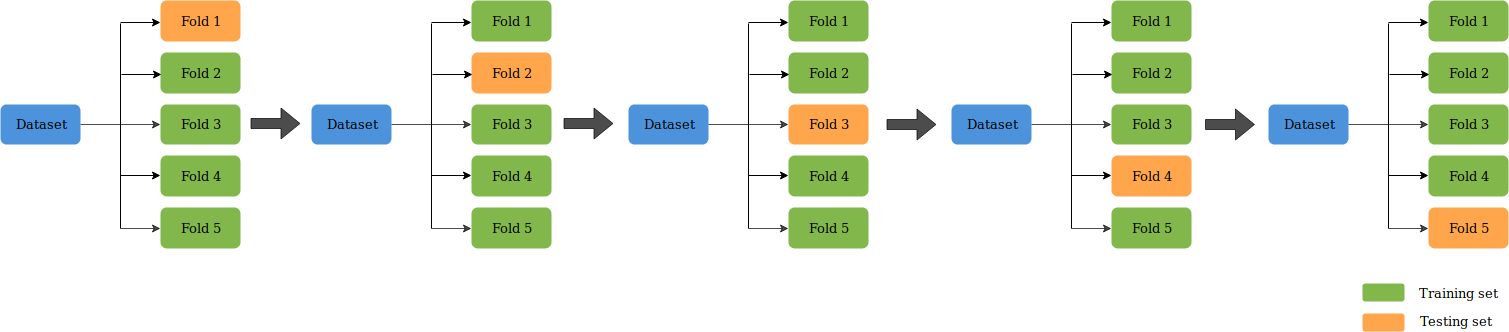
Cross-validation is a statistical technique used to evaluate the performance of a machine learning model without splitting our data for training and testing. This summer, we used a method of cross-validation known as “k-fold” to evaluate the skill of our classifier models, where k=10. In 10-fold cross-validation, a given data set is split into 10 sections where each section/fold is used as a testing set at some point. In the first iteration, the first fold is used to test the model and the rest are used to train the model. In the second iteration, 2nd fold is used as the testing set while the rest serve as the training set. This process is repeated until each fold of the 10 folds has been used as the testing set. The average score is then calculated for the cross-validation score.
Named Entity Recognition
Our team first ran Named Entity Recognition (NER) on a subset of our training set data, the 222 articles we labeled as “yes” innovation. The NER pipeline worked using the “dslim-bert-base” model and we compared its results to the company names that we had hand-labeled when classifying our training data.
Specifically, we ran each article through NER, and extracted the words that the model categorized as an organization, with the “ORG” tag, within the article. Along with the words themselves, we also extracted the confidence score associated with each word; this score indicates how confident the model is in its word recognition being correct.
Having all of the entities that the model “guessed” as organizations for a particular article, we then compared the model’s most confident guess, the one with the highest confidence score, to the name we had hand-labled when classifying our training data. Moreover, this was an exact string match in which the model’s guess was only considered correct if it was exactly the same as our hand-labeled company name.